# Install all libraries
! pip install pytorch-lightning wandb rdkit ogb deepchem torch
# Download all data
! mkdir data/
! wget https://raw.githubusercontent.com/schwallergroup/ai4chem_course/main/notebooks/02%20-%20Supervised%20Learning/data/esol.csv -O data/esol.csv
! wget https://raw.githubusercontent.com/schwallergroup/ai4chem_course/main/notebooks/03%20-%20Intro%20to%20Deep%20Learning/esol_utils.py -O esol_utils.py6 Week 3 tutorial 1 - AI 4 Chemistry
![]()
Table of content
- Supervised deep learning.
- Neural Networks.
- Creating a deep learning model.
0. Relevant packages
Pytorch
Based on the Torch library, PyTorch is one of the most popular deep learning frameworks for machine learning practitioners. We will learn to use PyTorch to do deep learning work. You can also browse the PyTorch tutorials and docs for additional details.
Pytorch Lightning
PyTorch Lightning is the deep learning framework for professional AI researchers and machine learning engineers who need maximal flexibility without sacrificing performance at scale. You can also browse its documentation for additional details.
Weights & Biases (W&B)
Weights & Biases is the machine learning platform for developers to build better models faster. Use W&B’s lightweight, interoperable tools to quickly track experiments, version and iterate on datasets, evaluate model performance, reproduce models, visualize results and spot regressions, and share findings with colleagues. You can also browse its documentation for additional details.
Exercise: Create a W&B account.
Go to W&B and create an account. We will be using this platform to track our experiments!
Set a random seed to ensure repeatability of experiments
import random
import numpy as np
import torch
# Random Seeds and Reproducibility
torch.manual_seed(0)
torch.cuda.manual_seed(0)
np.random.seed(0)
random.seed(0)1. Supervised Deep Learning
From last session we should already be familiar with supervised learning: is a type of machine learning that involves training a model on a labeled dataset to learn the relationships between input and output data.
The models we saw so far are fairly easy and work well in some scenarios, but sometimes it’s not enough. What to do in these cases?

Deep Learning
Deep learning is a subset of machine learning that involves training artificial neural networks to learn from data. Unlike traditional machine learning algorithms, which often rely on hand-crafted features and linear models, deep learning algorithms can automatically learn features and hierarchies of representations from raw data. This allows deep learning models to achieve state-of-the-art performance on a wide range of tasks in chemistry, like molecular property prediction, reaction prediction and retrosynthesis, among others.
Data: Let’s go back to the ESOL dataset from last week.
We will use this so we can compare our results with the previous models. We’ll reuse last week’s code for data loading and preprocessing.
from esol_utils import load_esol_data
(X_train, X_valid, X_test, y_train, y_valid, y_test, scaler) = load_esol_data()2. Neural Networks
Neural Networks are a type of machine learning model that is designed to simulate the behavior of the human brain.
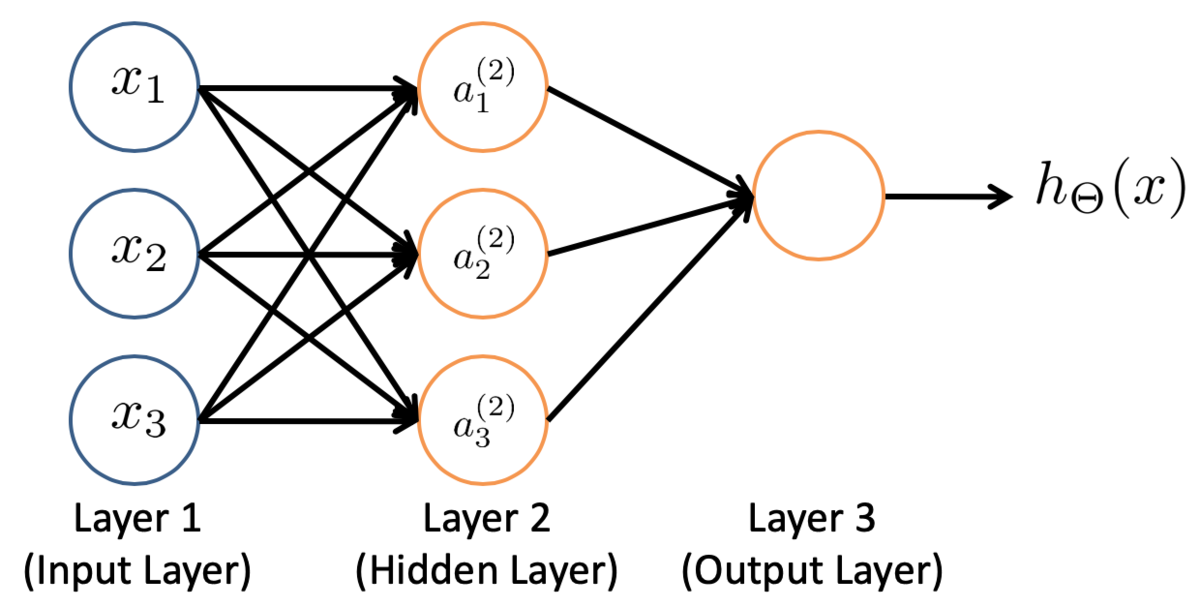
They consist of layers of interconnected nodes, and each node applies a linear function to its inputs. Non-linear activation functions are used to introduce non-linearity into the model, allowing it to learn more complex patterns in the data.
import os
import torch
import wandb
from torch import nn
import torch.nn.functional as F
import pytorch_lightning as pl
from torch.utils.data import DataLoader
from pytorch_lightning.loggers import WandbLogger3. Creating a deep learning model.
Creating DL models is fairly easy nowadays, specially thanks to libraries like Pytorch Lightning. They do most of the work for you, but they still alow you to have a lot of control over your models.
To use Pytorch Lightning, we first need to know about classes.
Think of a class as a template or a set of instructions for creating objects with specific properties and behaviors. These objects are called instances of the class.
For example, let’s say you want to make a program to represent dogs.
class Dog:
def __init__(self, name, color):
self.name = name
self.color = color
def say_your_name(self):
print(f"My name is {self.name}")
In this example, a dog has two attributes: name and color. It also has a method: say_your_name.
Now we can create as many dogs as we want! For example
lassie = Dog(name = "Lassie", color = "White")
pluto = Dog(name = "Pluto", color = "Yellow")And we can access their methods as follows:
pluto.say_your_name() # Output: "My name is Pluto"Now let’s define a NeuralNetwork class.
- What is each part?
__init__is where we specify the model architecture, There are loads of layers (model parts) you can use, and it’s all defined here.training stepis one of our model’s methods. It updates the model paramters using an optimizer.configure_optimizers, well, configures the optimizers 😅.
Here we define what optimizer to use, including learning rate.forwardspecifices what the model should do when an input is given.
class NeuralNetwork(pl.LightningModule):
def __init__(self, input_sz, hidden_sz, train_data, valid_data, test_data, batch_size=254, lr=1e-3):
super().__init__()
self.lr = lr
self.train_data = train_data
self.valid_data = valid_data
self.test_data = test_data
self.batch_size = batch_size
# Define all the components
self.model = nn.Sequential(
nn.Linear(input_sz, hidden_sz),
nn.ReLU(),
nn.Linear(hidden_sz, hidden_sz),
nn.ReLU(),
nn.Linear(hidden_sz, 1)
)
def training_step(self, batch, batch_idx):
# Here we define the train loop.
x, y = batch
z = self.model(x)
loss = F.mse_loss(z, y)
self.log("Train loss", loss)
return loss
def validation_step(self, batch, batch_idx):
# Define validation step. At the end of every epoch, this will be executed
x, y = batch
z = self.model(x)
loss = F.mse_loss(z, y) # report MSE
self.log("Valid MSE", loss)
def test_step(self, batch, batch_idx):
# What to do in test
x, y = batch
z = self.model(x)
loss = F.mse_loss(z, y) # report MSE
self.log("Test MSE", loss)
def configure_optimizers(self):
# Here we configure the optimization algorithm.
optimizer = torch.optim.Adam(
self.parameters(),
lr=self.lr
)
return optimizer
def forward(self, x):
# Here we define what the NN does with its parts
return self.model(x).flatten()
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.valid_data, batch_size=self.batch_size, shuffle=False)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size=self.batch_size, shuffle=False)Dataset class
To use Lightning, we also need to create a Dataset class.
It looks more complicated, but it actually allows a lot of flexibility in more complex scenarios! (so don’t be daunted by this 😉)
from torch.utils.data import Dataset
class ESOLDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return self.X.shape[0]
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
X_ = torch.as_tensor(self.X[idx].astype(np.float32))
y_ = torch.as_tensor(self.y[idx].astype(np.float32).reshape(-1))
return X_, y_
train_data = ESOLDataset(X_train, y_train)
valid_data = ESOLDataset(X_valid, y_valid)
test_data = ESOLDataset(X_test, y_test)# This will ask you to login to your wandb account
wandb.init(project="nn-solubility",
config={
"batch_size": 32,
"learning_rate": 0.001,
"hidden_size": 512,
"max_epochs": 100
})# Here we create an instance of our neural network.
# Play around with the hyperparameters!
nn_model = NeuralNetwork(
input_sz = X_train.shape[1],
hidden_sz = wandb.config["hidden_size"],
train_data = train_data,
valid_data = valid_data,
test_data = test_data,
lr = wandb.config["learning_rate"],
batch_size=wandb.config["batch_size"]
)
# Define trainer: How we want to train the model
wandb_logger = WandbLogger()
trainer = pl.Trainer(
max_epochs = wandb.config["max_epochs"],
logger = wandb_logger
)
# Finally! Training a model :)
trainer.fit(
model=nn_model,
)
# Now run test
results = trainer.test(ckpt_path="best")
wandb.finish()# Test RMSE
test_mse = results[0]["Test MSE"]
test_rmse = test_mse ** 0.5
print(f"\nANN model performance: RMSE on test set = {test_rmse:.4f}\n")Exercise:
Play with the hyperparameters, see what you get.
You may play around with hidden_sz, batch_sz, max_epochs, lr,
or even modify the architecture of our neural network i.e. change the number of layers, activation function, etc.